PCA (Principle Component Analysis) 개요
# PCA
(주성분분석법,
Principle Component Analysis)
# 목적
➊ 데이터의 차원축소
(특징추출)
➋ 데이터의 고유정보를 최대한 유지
# 통계적 배경지식
➊ 원래 데이터들이 퍼진정도를 고유정보로 볼 수 있음
(= 각 데이터간 거리)
➋ 고유정보가 두드러지도록, 데이터 집합이 가능한 넓게 퍼지도록
차원축소(사영, Projection)를 수행
(= 데이터의 분산이 가장 큰방향으로의 선형변환을 수행)
➌ 데이터의 공분산 행렬의
고유치가 가장 큰 값을 가지는 고유벡터가 분산이 가장 큰 방향이다.
➍ 고유치가 큰 순서대로 K개를 뽑아
K차원으로 축소할 수 있다.
(K차원 변환행렬 W를 구성)
# PCA 알고리즘 수행 단계
➊ 입력데이터 X의 평균 μ(X), Σ(X)를 계산
➋ 고유치 분석을 통해 공분산 Σ(X)의
고유치행렬(A)과 고유벡터행렬(U)를 계산
$\sum_{x}$=$UAU^{T}$
➌ 고유치 값이 큰 것 부터 순서대로 K개의 고유치
{A1,A2,A3, ..., Ak} 를 선택
➍ 선택한 고유치에 대응되는 고유벡터를
열벡터로 가지는 변환행렬 W 생성
➎ 선형변환(차원축소)된 Y를 얻음
$Y=W^{T}X$
# 목적함수 & 설명력
➊ 목적 : 차원 축소로 인해 손실되는 정보량을 최소화
➋ 목적함수 J(W)
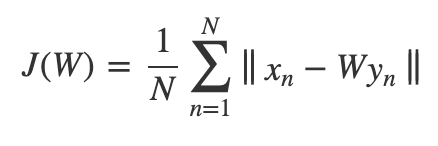
➌ 설명력 : 변환된 데이터가 원본 데이터를 얼마만큼 설명가능한가의 척도
(0~1사이 실수값)

보통 설명력을 일정상수(ex_ 0.97) 이상이 되게 끔 차원축소를 진행
# PCA 특성 및 한계점
# 장점
➊ 데이터 분석에 대한 특별한 목적이 없는 경우에 합리적
➋ 고차원의 데이터를 손실을 최소화하여 효율적으로 축소가능
# 단점
➊ PCA는 비교사 학습임
교사학습이 목적인 경우에, 분류의 핵심정보 손실 초래
➋ 선형변환의 한계를 가짐
(비선형구조를 반영못함)