Hadoop) YARN 의 등장 배경과 아키텍쳐 및 하는일
이 글을 읽기전에 분산시스템(쿠버네티스, HDFS)의 아키텍쳐에 대한 글을 읽고 오시는 것을 추천드립니다.
# YARN 등장 배경
Hadoop v1 에서는 Job Tracker 가 병렬처리의 클러스터의 자원관리와 애플리케이션의 라이프사이클 관리를 모두 담당하여 병목현상이 발생했었다.
이러한 병목현상을 개선하기 위해 YARN 아기텍쳐가 도입되었고, Hadoop v2 부터 등장한 개념이다.
좋은 분산시스템이 갖춰야 할 핵심요소는 스케줄링(scheduling)과 리소스관리(resource management) 기능이다.
하둡에서는 리소스할당과 애플리케이션을 스케줄링하는 역할을 하는 것이 바로 YARN(Yet Another Resource Negotiator)이다.
# YARN을 포함하는 하둡 아키텍쳐
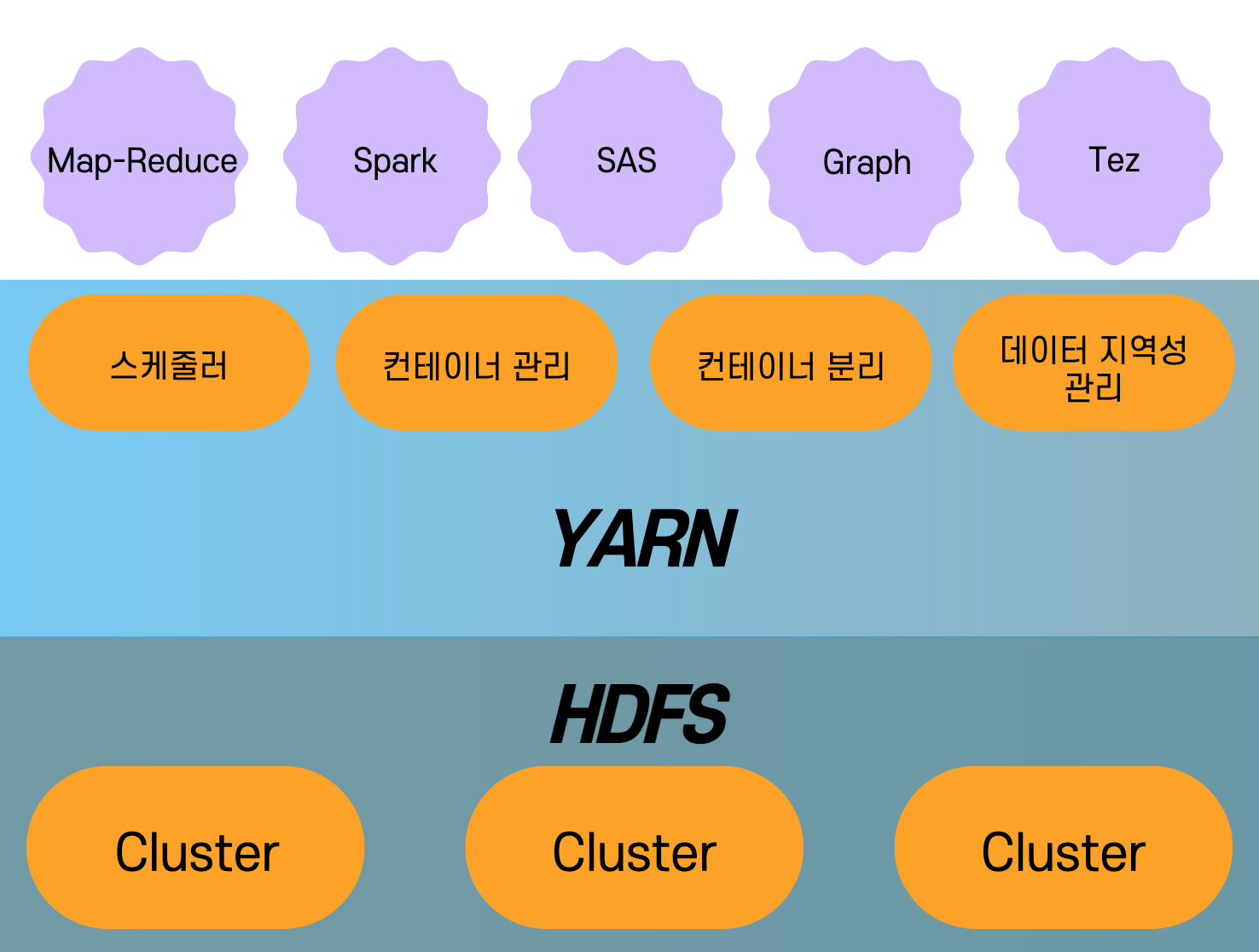
# YARN이 하는 일
요약하자면, YARN은 클러스터 전체에 계산을 분산하고 HDFS에 보관된 데이터를 확장 가능한 방식으로 처리하는 방법을
추상화 해서 제공한다.
1. 스케줄링 & 리소스관리
- 교체가능한(pluggable) 스케줄링 시스템을 지원한다.
(사용자당 리소스 제한, 작업대기열당 리소스 할당량 등에 대한 환경설정을 스케줄러에 입력할 수 있다)
- YARN은 각 클러스터당 하나씩 있는 RM(Resource Manager)을 실행시킨다.
- RM(Resource Manager)은 NM(Node Manager)와 통신하며, 필요시 AM(Application Manager)를 실행시킨다.
- 요청된 작업에 따라 컨테이너의 수가 달라질 것이며, 그를 총괄하는게 AM이고, AM은 NM에게 컨테이너 할당을 부탁한다.
* 하나의 클러스터에는 여러개의 노드가 있다.
참조 : developer-ping9.tistory.com/92?category=877707
# 하둡의 RM 작업할당 개요
- MR은 Map-Reduce를 뜻한다

2. 컨테이너 관리 & 분리
- YARN은 클러스터의 리소스를 컨테이너로 분할한다.
- 컨테이너 비공개(private) 설정, 사용자별 분리, 지연 후 작업시작도 지원
3. 데이터 지역성 관리
- 데이터 지역성도 리소스화 하여, 특정 컨테이너가 특정 데이터와 가장 가깝게 연결된 클러스터에서 실행되도록 한다.