-
하둡 HDFS 개요 (101 of Hadoop Distributed File System)Distributed File System/Hadoop 2020. 11. 30. 18:36
# 분산컴퓨팅의 필요성
- 규모가 방대한 빅데이터 환경에서는 기존 파일 시스템 체계를 그대로 사용할 경우 많은 시간과 높은 처리비용을 발생시킴
- 대용량 데이터 분석 및 처리는 여러대의 컴퓨터를 이용하여 작업을 분배하고, 다시 조합하며, 일부 작업에 문제(Fault)가 생겼을 경우, 해당 부분만 재처리가 가능한 분산 컴퓨팅 환경이 필요
# HDFS(Hadoop Distributed File System)
- GFS(Google File System)과 Map-Reduce 논문을 기초로 한 파일시스템
- 하나의 서버가 아닌, 여러 개의 서버에서 설치되어 서비스 됨 (분산컴퓨팅)
- HDFS만을 위한 별도의 스토리지를 요구치 않으며, 일반 로컬디스크를 이용하여 확장하는 구조
- 분산처리 연산에 대하여 Master/Slave 구조를 가진 시스템
# Map-Reduce
- 여러 노드에 Task를 분배하는 방법
- Map : 대용량 데이터에서 필요 분석 대상만 추출 (잘못된 레코드 제거) 하는 함수
# {Key-Value} 쌍 Input
# {Key-Value} 쌍 Output
- Map과 Reduce 사이에 Suffling, Sorting, Flitering 이 존재 할 수 있음.
- Reduce : 중복 데이터를 제거(병합)하는 함수 (보통 키 값(=해쉬 값)이 같으면 같은 리듀서에서 처리)
- 즉, 방대한 데이터에서 필요한 데이터로 매핑 및 추출하는 과정이다.
# Cluster of Hadoop
- HDFS 클러스터 = 하나의 Name Node(Master) + 다수의 Data Node(Slave)
- Name Node(Master Node) : 메타데이터(이름&위치 등)을 관리하는 노드
- Data Node : 실제 데이터의 저장을 담당하는 노드
- Execution : 같은 네트워크상 서로 다른 서버에서 여러개의 Demon을 실행한다는 뜻
- Demon의 종류 : NameNode, JobTracker, Secondary NameNode, DataNode, TaskTracker
# NameNode(Master Node)
- 파일시스템의 트리와 트리안의 모든 파일 및 디렉토리에 대한 메타 데이터를 유지
- 네임노드가 손상되면 파일을 재구성하는 방법을 알 수 없음
=> 메타데이터의 지속상태(persistent state)를 백업
=> Secondary NameNode 운영 (주 네임노드의 상태에 뒤쳐지기 때문에, 어느 정도 데이터손실이 있음)
# JobTracker
- Master로서 Map-Reduce의 전체적 실행을 감독하는 스케줄러
- Task 에 대한 실행계획을 결정
- 실행되는 모든 Task 모니터링 + Task 실패시, Task 재실행
- 하나의 Cluster에는 하나의 JobTracker만 존재
# Edit Log
- Master Node가 생성하는 파일
- HDFS내의 모든 파일트랜잭션을 저장
- HDFS가 restart 할 경우, (edit log+fs-image)를 병합해서 인메모리 형태로 메타데이터를 로딩
- 별도 용량제한이 없어, edit log 가 지나치게 클 경우, 로딩실패 또는 로딩지연으로 HDFS가 구동되지 못할 수 있음
# Secondary NameNode(보조 네임노드, 체크포인팅 서버)
- NameNode의 Edit Log를 주기적으로 축약시켜주는 역할을 수행
- Check Point : 축약작업을 수행한 지점
- 따라서 각 Check Point 까지만 백업이 가능
- 체크포인팅을 하지 않더라도 HDFS는 아무런 문제없이 구동되므로, 클러스터 구성시 보조네임노드가 정상적으로 동작하는지 꼭 확인할 것

출처 : https://nive.tistory.com/92 # DataNode(Slave Node)
- 사용자의 HDFS 파일 I/O는 블록단위(64MB)로 이루어진다.
- 사용자가 HDFS 파일 입출력을 요청하면, MasterNode는 어느 DataNode에 위치한지 사용자에게 알려준다.
- 보통 데이터들은 다수의 DataNode에 분산 저장 되어 있다. (데이터 복제로 유실방지, 블록의 백업저장소 역할)
- DataNode들은 블록의 최신 메타데이터를 유지하도록 NameNode에게 계속 보고한다. (블록의 생성, 삭제, 이동등)
# TaskTracker
- JobTracker의 하위 스케줄러, Slave 계층에 있음
- 각 DataNode(Slave)에 할당된 Task의 실행을 담당
- TaskTracker는 JobTracker와 지속적으로 통신(HeartBeat)한다.
- Heartbeat 메세지가 TaskTracker로 부터 정해진 주기안에 도착치 않으면, 해당 TaskTracker에 문제발생으로 판단, 해당 작업을 다른 노드에 할당한다.
# 하둡 클러스터의 전체적 구성
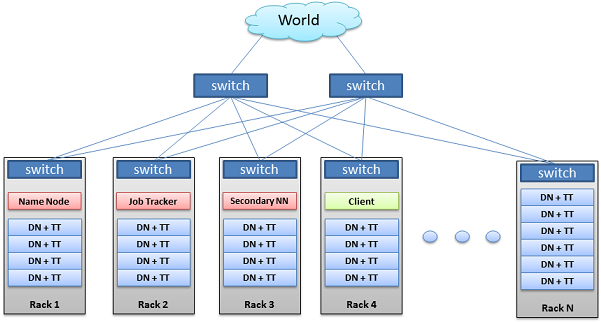
출처 : https://ryufree.tistory.com/226
# 참조 사이트
하둡 분산 파일 시스템(HDFS, Hadoop Distributed File System) [1편]
빅데이터 환경에서 생산되는 데이터는 그 규모와 크기가 방대하기 때문에 기존의 파일 시스템 체계를 그대로 사용할 경우 많은 시간과 높은 처리 비용을 필요로 합니다. 따라서 대용량의 데이
ryufree.tistory.com
HDFS 개념
하둡은 여러 서버에 걸쳐 있는 분산된 저장 리소스들을 논리적으로 하나로 엮은 상위 레벨의 파일시스템이라 볼수 있다. 물론 각 서버 내에서는 그 서버의 OS에 사용하는 NTFS나 EXT4와 같은 물리
nive.tistory.com
[하둡] 맵리듀스(MapReduce) 이해하기
맵리듀스는 여러 노드에 태스크를 분배하는 방법으로 각 노드 프로세스 데이터는 가능한 경우, 해당 노드에 저장됩니다. 맵리듀스 태스크는 맵(Map)과 리듀스(Reduce) 총 두단계로 구성됩니다. 간
12bme.tistory.com
맵리듀스(MapReduce)란? -1-
맵리듀스(MapReduce)란? : 대용량 데이터를 처리를 위한 분산 프로그래밍 모델 - 구글에서 2004년 발표한 소프트웨어 프레임워크 - 타고난 병행성(병렬 처리 지원)을 내포 - 누구든지 임의로 활용할
over153cm.tistory.com
728x90'Distributed File System > Hadoop' 카테고리의 다른 글
Hadoop) Map-Reduce 개념과 예시 & YARN에 기반한 처리엔진 Spark (0) 2021.01.17 Hadoop) YARN 의 등장 배경과 아키텍쳐 및 하는일 (0) 2021.01.17 데이터과학) 빅데이터 시대가 도래한 이후, 기업의 변화와 변화의 근간에 대하여 (with Hadoop) + 비즈니스 활용사례 (0) 2021.01.17