-
[Spring JPA] 복합키(PK)의 성능을 알아보자!Back End/Spring Data JPA 2022. 1. 26. 16:52
* 복합키 구현시 equals()와 hashCode() 메소드는 복합키 비교에서 사용되므로 꼭 Override해주자.
필자는 복수전공자라 시간표도 안맞고 학점채우기에 급급해 데이터베이스과목을 수강하지 못했다.
그래서 혼자 SQLD 라도 공부하고 자격증을 따면 비등하지 않을까 했는데... 튜닝부분이 핵심인 것을 이제야 깨닫는 중이다.
추후에 데이터베이스 성능튜닝에 대한 공부를 할 것이지만, 그에 앞서 JPA로 간단한 성능측정을 해보았다.
필자가 구글링을 통해 알아낸 정보에 기반한 실험이다.
(카더라 통신일 경우가 많으므로, 추후 검증이 필요하다)
1. 검색조건에 자주 등장하는 컬럼은 인덱스처리를 하면 검색성능이 빨라진다.
2. 인덱스처리를 하면, 데이터 삽입/수정/삭제 마다 B-Tree 자료구조를 유지해야하므로 정렬비용이 있다.
3. 인덱스는 Unique하지 않을 수도 있지만, PK는 Unique 하다.
4. 그러므로 PK는 B-Tree 자료구조가 아닌 튜플로 관리한다. (이게 사실이라면 PK는 정렬비용이 없을 수 있다.)
5. 대부분의 포스팅에서는 PK도 인덱스와 똑같이 관리된다는 식으로 말한다.
# 실험할 사항
1. PK를 복합키로 구성했을 경우, 복합키의 한 필드만 검색조건에 넣었을 때의 성능분석
2. em.find(복합키) 와 JpaNamedQuery(복합키)의 성능비교
3. PK나 Index가 아닌 필드로 조회시 성능비교
# 실험 Let's Go!
>> Book 과 cBook 엔티티
cBook은 author와 name의 복합키로 PK를 구성하였다.
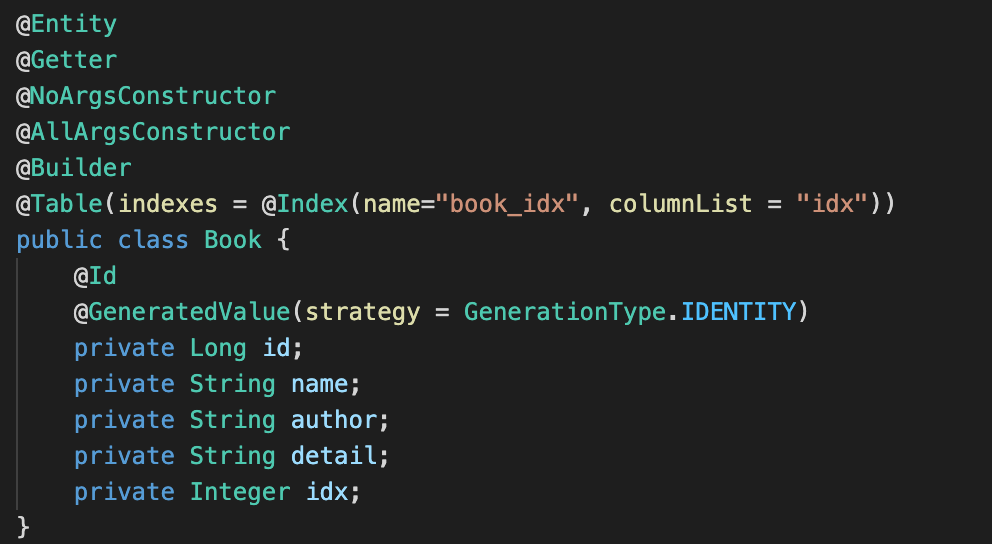
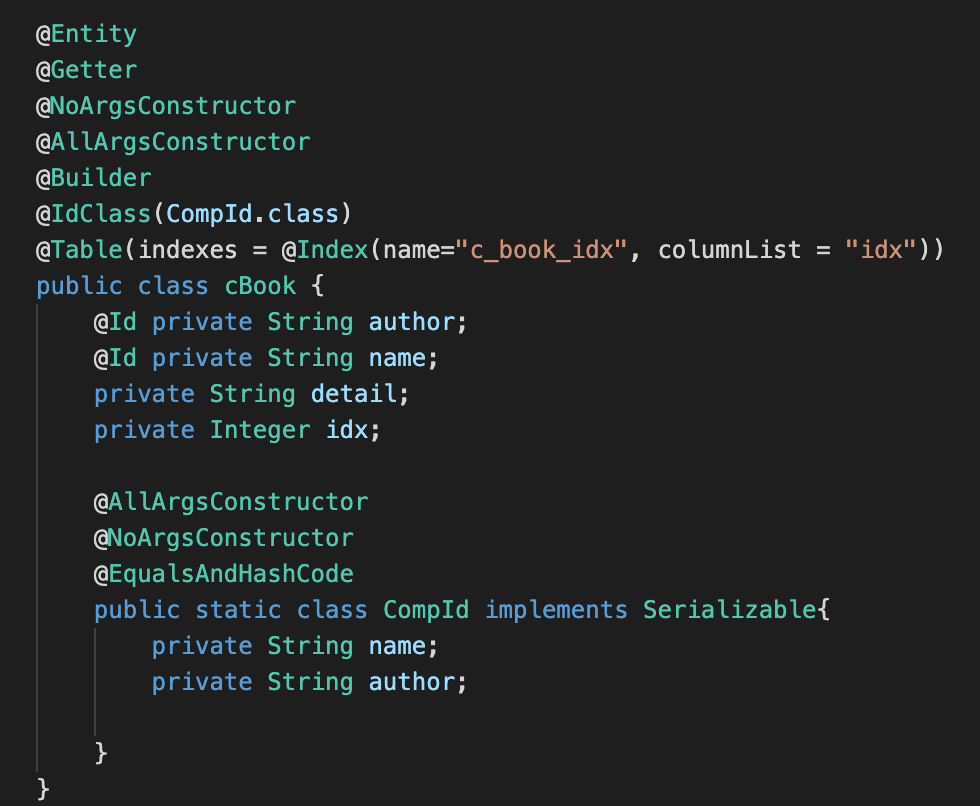
Book 엔티티 // cBook 엔티티 >> DDL 쿼리 확인
작업하는 테스트 프로젝트에 다른 테이블도 많아 복붙으로 대신하겠다.
Hibernate: create table book ( id bigint generated by default as identity, author varchar(255), detail varchar(255), idx integer, name varchar(255), primary key (id) ) Hibernate: create table c_book ( author varchar(255) not null, name varchar(255) not null, detail varchar(255), idx integer, primary key (author, name) ) Hibernate: create index book_idx on book (idx) Hibernate: create index c_book_idx on c_book (idx)>> 테스트코드
테스트 코드는 너무 길어서 접은글로 설정해두었다.
테스트 코드에 쓰인 NamedQuery들은 서로 같은 쿼리를 날리는지, 의도한 쿼리를 날리는지 다 체크하였다.
혹여나 테스트코드를 복붙해서 직접 해보시는 분들을 위해,
30만건짜리 테스트를 할때는 yml파일의 show_sql 옵션을 false로 지정해야 출력문의 홍수에 빠지지 않으실 것이다.더보기@DataJpaTest @Import(JpaConfig.class) public class compositeKeyTest { @Autowired BookRepository bookRepository; @Autowired cBookRepository cBookRepository; @Autowired EntityManager em; @Test void showSchema(){ } @Test void showQuery(){ List<Book> books = new ArrayList<>(); List<cBook> cBooks = new ArrayList<>(); String[] authors = {"Brian","Matt","Sun","Torr","SpiderMan"}; String[] names = {"사탕과함께사라지다","진격의노인","레프트오버","투피스","아이엠넘버포"}; //5개 for(int i=0; i<5; i++){ books.add( Book.builder().name(names[i%5]).author(authors[i%5]).detail("KK").idx(i).build() ); cBooks.add( cBook.builder().name(names[i%5]).author(authors[i%5]).detail("KK").idx(i).build() ); } bookRepository.saveAll(books); cBookRepository.saveAll(cBooks); em.flush(); em.clear(); Long startTime= System.currentTimeMillis(); System.out.println("#Start! : "+ (startTime/1000)); System.out.println("#Start! : "+ (startTime/(1000*60))); System.out.println("#Start! : "+ (startTime/(1000*60*60))); System.out.println("#BookmarkRepository Item Count : "+bookRepository.count()); em.flush(); em.clear(); System.out.println("#cBookmarkRepository Item Count :"+cBookRepository.count()); em.flush(); em.clear(); bookRepository.findByAuthor("Sun"); em.flush(); em.clear(); cBookRepository.findByAuthor("Sun"); em.flush(); em.clear(); bookRepository.findByAuthorAndName("Sun","레프트오버"); em.flush(); em.clear(); cBookRepository.findByAuthorAndName("Sun","레프트오버"); em.flush(); em.clear(); CompId pk = new CompId("Sun", "레프트오버"); em.find(cBook.class, pk); em.flush(); em.clear(); bookRepository.findByDetail("KK"); em.flush(); em.clear(); cBookRepository.findByDetail("KK"); em.flush(); em.clear(); bookRepository.findByIdx(2); em.flush(); em.clear(); cBookRepository.findByIdx(2); em.flush(); em.clear(); } @Test void test(){ List<Book> books = new ArrayList<>(); List<cBook> cBooks = new ArrayList<>(); String[] authors = {"Brian","Matt","Sun","Torr","SpiderMan"}; String[] names = {"사탕과함께사라지다","진격의노인","레프트오버","투피스","아이엠넘버포"}; //30만개 int cnt =1; for(int i=0; i<300_000; i++){ if(i%5==0){ cnt++; } books.add( Book.builder().name(names[i%5]+cnt).author(authors[i%5]).detail("KK").idx(i).build() ); cBooks.add( cBook.builder().name(names[i%5]+cnt).author(authors[i%5]).detail("KK").idx(i).build() ); } bookRepository.saveAll(books); cBookRepository.saveAll(cBooks); em.flush(); em.clear(); System.out.println("#BookmarkRepository Item Count : "+bookRepository.count()); em.flush(); em.clear(); System.out.println("#cBookmarkRepository Item Count :"+cBookRepository.count()); em.flush(); em.clear(); Long startTime; Long endTime; Long result; Long[] sum= new Long[100]; Arrays.fill(sum, 0L); Queue<Long> results= new LinkedList<>(); cnt=0; int idx=0; while(cnt<20){ //20 회 평균 idx = 0; //1 startTime= System.currentTimeMillis(); bookRepository.findByAuthor("Sun"); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //2 startTime= System.currentTimeMillis(); cBookRepository.findByAuthor("Sun"); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //3 startTime= System.currentTimeMillis(); bookRepository.findByAuthorAndName("Sun","레프트오버10"); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //4 startTime= System.currentTimeMillis(); cBookRepository.findByAuthorAndName("Sun","레프트오버10"); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //5 startTime= System.currentTimeMillis(); //엔티티 필드 ID순서(테이블필드순서)랑 복합키클래스이 필드순서가 일치해야 인덱스를 탄다.......................;;;;;; CompId pk = new CompId("레프트오버10","Sun"); em.find(cBook.class, pk); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //6 startTime= System.currentTimeMillis(); bookRepository.findByDetail("KK"); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //7 startTime= System.currentTimeMillis(); cBookRepository.findByDetail("KK"); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //8 insert 성능 Book book = Book.builder().name(names[0]).author(authors[0]).detail("KK").build(); startTime= System.currentTimeMillis(); bookRepository.save(book); em.flush(); em.clear(); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; //9 cBook cbook = cBook.builder().name(names[0]).author(authors[0]).detail("KK").build(); startTime= System.currentTimeMillis(); cBookRepository.save(cbook); em.flush(); em.clear(); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; //10 book = Book.builder().name(names[0]).author(authors[0]).detail("KK").idx(15_000).build(); startTime= System.currentTimeMillis(); bookRepository.save(book); em.flush(); em.clear(); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; //11 cbook = cBook.builder().name(names[0]+"@").author(authors[0]).detail("KK").idx(15_000).build(); startTime= System.currentTimeMillis(); cBookRepository.save(cbook); em.flush(); em.clear(); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; //12 Index 로 조회 startTime= System.currentTimeMillis(); bookRepository.findByIdx(13_000); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); //13 startTime= System.currentTimeMillis(); cBookRepository.findByIdx(13_000); endTime= System.currentTimeMillis(); result = endTime-startTime; sum[idx++]+=result; em.flush(); em.clear(); cnt++; } for(int i=0; i<13; i++){ results.add(sum[i]/cnt); } System.out.println("#1 GenralBook.findByAuthor >>> : " + (results.poll())); System.out.println("#2 CompositeBook.findByAuthor >>> : " + (results.poll())); System.out.println("#3 GenralBook.findByAuthorAndName >>> : " + (results.poll())); System.out.println("#4 CompositeBook.findByAuthorAndName >>> : " + (results.poll())); System.out.println("#5 CompositeBook.findByPK >>> : " + (results.poll())); System.out.println("#6 GeneralBook.findByDetail >>> : " + (results.poll())); System.out.println("#7 CompositeBook.findByDetail >>> : " + (results.poll())); System.out.println("#8 GeneralBook.insert >>> : " + (results.poll())); System.out.println("#9 CompositeBook.insert >>> : " + (results.poll())); System.out.println("#10 GeneralBook.insert >>> : " + (results.poll())); System.out.println("#11 CompositeBook.insert >>> : " + (results.poll())); System.out.println("#12 GeneralBook.findByIdx >>> : " + (results.poll())); System.out.println("#13 CompositeBook.findByIdx >>> : " + (results.poll())); System.out.println("Queue Size : "+ results.size()); } }>> 실험결과


# 확인 사항
1. PK의 검색성능은 어마어마하다.
주로 검색되는 필드를 PK로 둔다면 많은 이점을 누릴 수 있을 것 같다.
삽입/삭제에 대한 정렬오버헤드는 지금 단계에서 고민하지 않아도 될 것 같다.
정말로 데이터가 무지막지하게 많아져서, 삽입/삭제 오버헤드가 눈에 띄게 된다면 샤딩으로 분산시켜주는 것도 하나의 방법이다.2. 인덱스의 검색성능 또한 어마어마하다.
분명 Insert 시 정렬비용이 생겨 레코드가 많을때는 불리하다고 여러 포스팅에서 말하고 있는데
30만건이라 눈에 안띄는 것 같다. (기수정렬 같은 경우에는 O(1) 에 끝나버리니까)
그리고 이미 정렬되어있는 자료에 추가데이터를 넣어 정렬하니 제일 가성비좋은 삽입정렬 알고리즘을 사용하지 않을까 싶다.
데이터가 억단위가 넘어가야 그제서야 정렬오버헤드가 눈에 보이지 않을까? 하는 추측을 해본다.3. PK를 복합키로 구성했을 경우, 개개의 컬럼은 자료구조에 의해 관리되지 않는다.
복합키의 순서쌍을 튜플형식으로 관리한다고 일단 생각해두면 좋을 것 같다.
4. em.find 와 JpaNamedQuery 의 성능차이는 없다.
사실 예제코드의 생성자 (CompId) 의 순서에 따라 결과가 달라지는 것을 목격했는데, 20회 평균을 내니까 차이가 0으로 수렴해서 신경안써도 될 것 같다.
(지인분께서 검색순서에 따라 실행계획이 달라져서 FullScan을 할 수도 있다고 하셔서 나름 걱정했는데 내 맥북이 아팠던 것 같다.)5. PK를 복합키로 구성한 경우, 복합키의 순서쌍은 Unique 해야한다
당연한 것인데, 처음시도하다보니 실수로 for문에서 같은값을 집어넣어 Book 30만건, cBook 5건이 저장되는 상황이 발생했다.
복합키를 PK로 사용한다면 주의해야 할 점이다.
Unique 하게 순서쌍을 구성할 수 없다면, Index를 이용하자.# 의문사항 (추후 공부하면서 해결해야 할 문제)
1. findByAuthor 와 findByDetail은 둘다 PK가 아닌 값이고, 30만개의 레코드를 전부 탐색할 것인데 수행시간차이가 확연함
findByAuthor는 6만개를 반환, findByDetail은 30만개를 반환해서 List에 넣는작업에 의한 오버헤드가 아닐까 추정
2. 10번과 11번은 일부러 정렬하기 귀찮게 idx의 중간값인 15_000을 넣었는데 퀵정렬과 같은 Pivot 값 때문에 더빠른것인가?
idx에 null 값을 세팅한 8,9번보다 빠름
엥 중간값은 150_000 인데,,,, 실수 했다... ㅎ3. PK는 과연 정렬비용이 있을까?
필자의 맥북은 8년지기 친구라 레코드 수를 더 늘려보지 못했다.
이는 서적이나 현업 DBA께 꼭 여쭈어 해결하자...!
근데 현업에 있는 예제ERD들을 보면, PK가 무지막지하게 많은 경우를 관찰할 수 있는데.. 정렬비용이 없어서 PK로 두는걸까?728x90'Back End > Spring Data JPA' 카테고리의 다른 글
[Spring JPA] How to retrieve Only SuperClass from a class hierarchy. (0) 2022.01.28 [Spring JPA] Interface-Based Projection doesn't work. (0) 2022.01.28 [Spring JPA] @OneToOne 에서 @MapsId 를 이용해 컬럼갯수를 줄여보자! (0) 2022.01.26 [Spring JPA] @OneToMany 에서 @MapsId 사용하기 (2) 2022.01.24 [Spring JPA] referencedColumnName 사용시 주의점 (Feat. 프록시) (0) 2022.01.21