-
Pandas - 대용량데이터 전처리 꿀팁 (멀티인덱스, groupby, isin, select_dtypes)프로그래밍 언어/Python 2021. 2. 2. 14:12
# 대규모 데이터의 예시
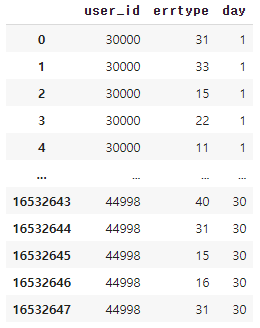
대용량 데이터 예시, 1600만건의 행(instance)
소규모 데이터가 아닌 대용량 데이터를 다뤄보면,
for 문으로 데이터를 정제하는 습관을 지양해야 할 필요성을 느낄 것이다.
또한, 변수의 저장도 최소한으로 다루어야 한다.
Hadoop이나 쿠버네티스 같은 분산컴퓨팅을 하지않고,
오직 컴퓨터 1대로 대용량데이터 전처리를 진행해야 한다면
변수를 생성(초기화)하면 할 수록 RAM이 가득차서 에러가 뜰 것이며,
for 문의 속도도 현저히 떨어진다.
왜냐면 파이썬은 메모리를 FLEX 하니까..!
필자 또한 부족하지만,
대용량 데이터를 다루며 깨달은 노하우를 공유하고자 한다.
큰틀은 아래와 같다.
1. Pandas 패키지를 최대한으로 이용하자
파이썬의 라이브러리는 대부분 C++로 만들어져 있다.
Numpy, Tensor 같은 라이브러리 또한 C++로 만들어져 있다.
메모리를 최소한으로 쓰도록, 코드의 실행속도가 최적화가 되도록
이미 여럿 똑똑한 분들이 힘을 합쳐 디자인 해 놓은 라이브러리는
최대한 이용해야한다!
2. 필요없는 변수는 생성을 지양하며,
사용이 끝난 변수는 파일로 저장하거나 RAM에서 삭제해주자!

google colab의 RAM 및 DISK 용량 필자는 Google 의 Colab을 자주쓰는데,
RAM 12GB가 커보이지만 대용량 데이터를 작업해보면 순식간에 가득 차버린다.
연산을 위해 변수를 저장하고 있는 장소 또한 RAM 이므로,
한정된 RAM을 가지고 있다면, 이를 유의하자.
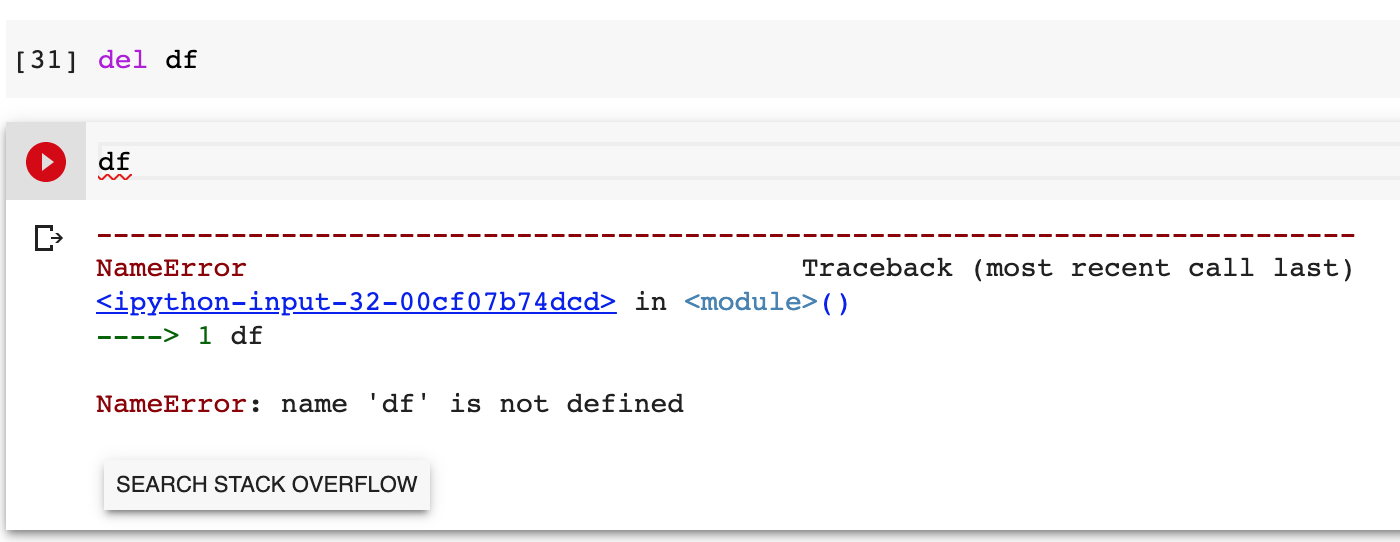
파이썬의 변수 삭제 명령어는 del 이다.
# del 명령어로 변수를 RAM에서 삭제해주자

# del 명령어로 삭제한 변수를 다시 불러보면 not defined 라 에러가 뜬다.
(잘 삭제 되어 더 이상 해당 변수가 존재하지 않는다는 뜻이다.)
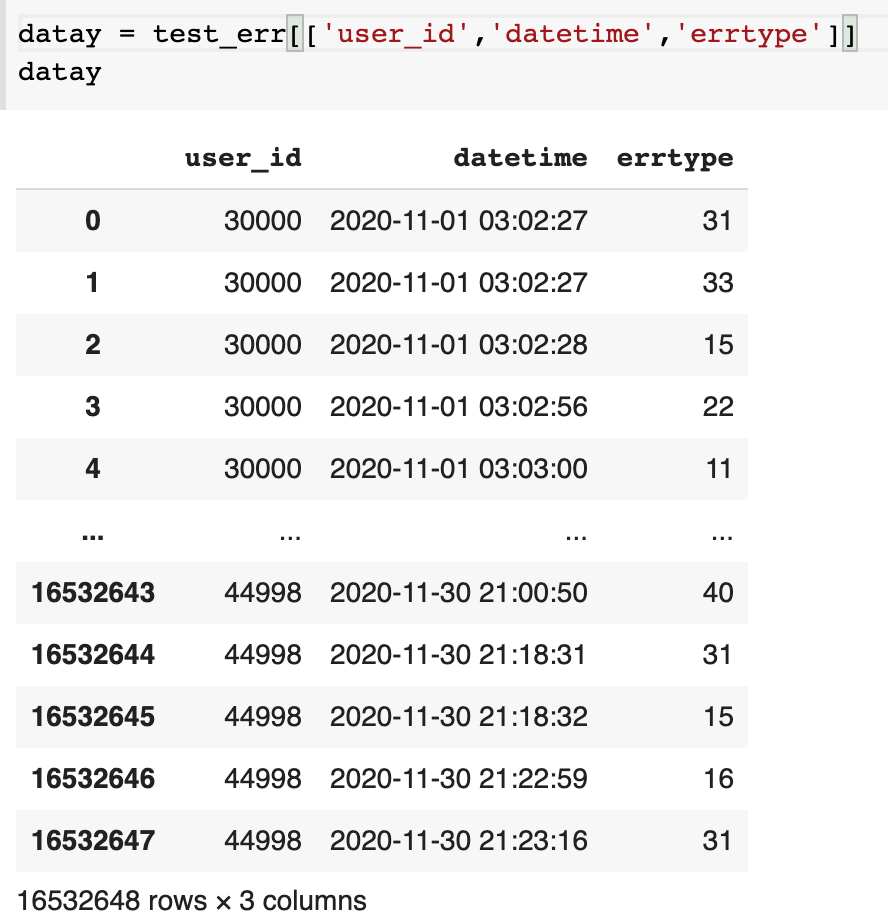
# 필요한 만큼의 변수를 할당해주는 센스!
많은 컬럼 중
사용할 컬럼만 변수에 저장한다!
# 파이썬 Pandas 패키지 중 대용량 데이터 처리에 유용한 함수들
1. select_dtypes(include = [] , exclude= [])
해당 데이터의 칼럼 수(차원)가 엄청 클 경우,
칼럼의 데이터 타입별로 뽑아 낼 수 있어 유용하다.
정형 데이터만 뽑아서 보고 싶을 때, 아주아주 유용하다.
(일일이 컬럼명을 입력할 필요가 없다)
include = ['bool', 'object']
형식으로 사용가능하다.

2. apply & isin
apply 같은 경우엔 for 문 보다는 훨씬 빠르나,
그렇게 빠르지 않음을 유의하자.
필자는 특정 데이터의 값에 접근하거나 변경할 때,
무작정 apply를 쓰는 경향이 있었는데,
특정 데이터의 조건이 무엇이냐에 따라 다르겠지만,
isin이 훨씬 빠르다.
3. groupby & size
SQL에서 넘어온듯한 이 함수는
카테고리별 어떠한 값의 소계를 낼때 유용하다.
사용예시를 보는 것이 훨씬 이해가 빠를 것이다.
# 대용량 데이터셋 예시
(변수명은 datax로 하겠다)

# grouby와 size의 혼용예시
id별 day별
day의 count 값을 구하는 예시이다.

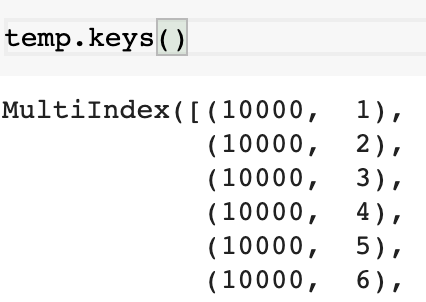
groupby, size 리턴값은 Series 이다.
출력을 들여다보면, 멀티인덱싱이 되어있는 것을 확인할 수 있는데,
이를 원하는 목표의 DataFrame으로 만들어주는 코드는 아래와 같다.

# 이 글을 읽으시는 분들께
이 포스팅은
제가 노하우를 발견할때마다 갱신할 예정입니다.
저는 컴퓨터학부를 복수전공중인 학부생이라
부족한점이 많습니다.
혹여나, 지나가는 선배님들께서 가지고 계신 노하우들을
공유해주신다면 정말정말 고맙겠습니다..! :D
728x90'프로그래밍 언어 > Python' 카테고리의 다른 글
Pandas - 조건에 따라 각각 다른 값 넣기, 서로다른 데이터프레임 Key 기준으로 Merge(Join) 하기, 특정 index에 접근하여 값 바꾸기 (0) 2021.01.11 Pandas - 조건에 맞는 컬럼 값 여러개 바꾸기 (4) 2020.12.24 파이썬 - 언더스코어 ( _ ) : Underscore (0) 2020.12.17 Python(파이썬) - 공분산행렬, 고유치 구하기(PCA 모듈 & 선형대수(np.linalg 모듈)), StandardScaler로 정규화하기, np.cumsum (0) 2020.12.02 Python(파이썬) - 누적합(Cumulative Sum) 구하기, 상삼각행렬, 하삼각행렬 만들기 (0) 2020.12.02